
Risk Intelligence
Alternatively: A pentester reads a book on Risk by Dylan Evans
Sometimes I read.
Most of the time, it’s books that might apply to my job, my hobbies, or in some way could be useful, or perhaps someone recommended me a book and I’ve forgotten what utility it may have had. Unfortunately, as I do not track who recommended the book, I don’t have any idea on who to thank or blame.
I recently read Risk Intelligence: How to live with uncertainty by Dylan Evans (https://www.amazon.com.au/Risk-Intelligence-How-Live-Uncertainty/dp/1451610912), which was about making meaningful and informed decisions around thinks which involve risk; i.e. Do I buy insurance for my iPhones screen in case it is dropped.
I’m unsure if it was good book, but it did give me a few ideas.
A day at the races
- The book starts off by citing a study by Stephen Ceci and Jeffrey Liker (Ref is 10.1037/0096-3445.115.3.255, thanks https://sci-hub.se) about people putting bets on horses.
- They were mostly the kinds of people you’d imagine sit around betting on horses during the day back in 1986
- People were interviewed and asked to bet on horses, while the authors compared these bets against outcomes
- They also asked about hypothetical races too, but that’s not as exciting for the point
Unsurprisingly, the study is called “A Day at the races: A Study of IQ, Expertise and Cognitive complexity”, and found that IQ was unrelated skilled performance at the racetrack (i.e. picking the right horse).
The authors went on to explain that the people better at betting were taking into consideration a number of factors, and had an idea of which ones to weigh more than others.
Risk Matrix
This actually seemed pretty applicable to $DayJob, I quote the following:
[...] I was in the company's head office, meeting with the risk management team.
It turned out that they had been using a popular risk management methodology that
involved first estimating the liklihood and impact of each risk on a simple three-point
scale (low, medium, high). Next, the likelihood and impact of each risk were plotted on
a so-called risk risk matrix in which different regions were defined as high, medium, or low risk
For those who haven’t seen, he’s describing something that looks like the following:
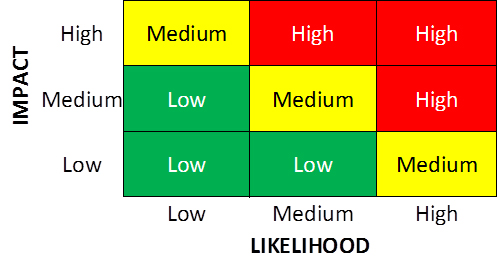
You’ve probably seen the same thing, if you’re not using something like CVSS (https://www.first.org/cvss/) you or your clients are probably doing something like the above.
These are mostly bullshit, and are unlikely to be too helpful - but as penetration testers our job is not to understand risk, just point out issues in some meaningful fashion.
Awkwardly, clients would state that the risk ratings given to them are by risk professionals, but penetration testers are not that, not are most Governnance, Risk and Compliance (GRC) experts.
Anyway, to continue with the quote:
Such scoring methods are relatively easy to create and teach. Consequently,
they have become very popular in a wide variety of business sectors.
Respected organisations have designed such methods and represent them
as best practices for thousands of users. For example, the US Army have
developed a weighted scoring-based method for evaluating the risk of missions.
The US Department of Health and Human Services uses a weighted scoring method
to determine vaccine allocations in the event of a pandemic outbreak, and NASA
uses a scoring method for assessments of risk in manned and unmaned missions.
Unsurprising that most places have something for these kinds of things, however:
I believe that these scoring methods are deeply flawed for many reasons. The
first and most fundamental problem is that they are only understood as the
initial estimates that serve as input, if you put garbage in, you get garbage
out. The initial estimates are usually provided by experts, but even experts
suffer from systemic errors and biases when estimating probabilities.
Furthermore, these methods fudge matters by using verbal scales in which risks
are characterised as "low", "medium" and "high" instead of asking users to
state numeric probabilities.
I agree in part about this kind of thing, however I’m unsure how to put a percentage likelyhood on someone exploiting cross site scripting. As stated above, with these risk matrices, we end up with fairly nonsense “verbal” scales.
He also points out the problem around how experts could just put garbage data in due to systemic errors and biases when estimating, i.e. “How skilled the average attacker is”.
For $DayJob, It might be more meaningful to talk about the likelihood of anyone caring about a particular application, if it’s on the internet, however this would probably end up in another broken framework. However, it should be noted that someone probably knew a bunch of systems sucked, then said systems achieved media attention, then were hacked subsequently.
Notably we could talk about recent US events, such as https://www.govtech.com/security/Anonymous-Claims-Responsibility-for-Minneapolis-PD-Cyberattack.html. If anyone saw the systems, they’d probably know it was only a matter of time, and with enough attention, someone eventually cared enough to do something. Generally we call these Issue Motivated Groups :)
Quoting the rest of the relevant bits would be tedious, but his approach from here was:
- Get people to state actual numbers, i.e.
- 10% chance we’ll get hacked this month (But no number on impact)
- 10% chance we’ll lose 2 million dolars of inventory
- They’d review these numbers every month, and adjust their expectations on probability
- With numbers, people were able to have better resolution on what mattered
- With the review process, they also were able to have a faster feedback loop on processes
This aimed more towards project blowouts and better outcomes, but a security impact could reasonably be treated in a similar fashion, albiet the numbers could be guessing.
The Availability hueristic
Another bit was very relevant to $DayJob, which was working through a list of biases that affect how we make up probability numbers. The most interesting one was the availability bias, which could be summarised off wikipedia shamelessly as follows:
The availability heuristic, also known as availability bias, is a mental
shortcut that relies on immediate examples that come to a given person's
mind when evaluating a specific topic, concept, method or decision.
This can come up often when scoping out likely paths to victory for penetration testers:
- What worked on your last gig is probably what you’ll try again
- If you haven’t had SQL injection in years, and forgotten about it, you might not look for it
His solution was around considering the probability of dramatic events, so it probably wasn’t too relevant in testing methodologies, but might be more valuable when considering how likely it is for an organisation to be completely owned by a bug, and if you have recently seen it in the news or not.
Meta: Spicy bits
A lot of this book seems to come down to not using weasly words unintentionally (or otherwise, if you’re naughty), to signal how sure you are on something happening. “Likely” could mean anything from 50-70% for one person, but your audience could think that means 90%. There was a bunch of citations around this in legal precidence, of “beyond reasonable doubt” and “balance of probabilities”, and times where the jury (i.e. non-experts asked to use expert language), did not have the same understanding as experts (i.e. the lawyers and judge), often to horrific effect.
There was a very spicy comment around how short sellers provide a useful corrective to epidemics of optism bias, which was in context of the global finacial crisis. Related, this is also applicable to our job as breakers to find weird things and not expect them to be fine.
The book goes into some ideas of mathematical models, cites some more things around cases where models are making people millions when gambling in Hong Kong, but also concedes that “true risk intelligence is not achieved simply by mathematical calculations”.
Theres a few mandatory references to unknown unknowns, Anton-Babinski Syndrome and Dunning-Kruger.
Meta: Citations
About a third of the book is references and citations, a lot of which I skimmed and they seemed to be:
- Peer reviewed
- Cited a lot
- Published with reputable places
- Actually said the same thing he said
I’m not an academic, so that’s probably about as good as I can get for filtering academic papers.
Meta: What I should have done instead
Practically, this book was pretty useless. It cited a bunch of things that most people are unlikely to follow, and just kept throwing comment after comment on different studies, but again as a non-expert in that field, it wasn’t terribly useful. It’s also unclear how to apply any of this.
Next time I might just go straight to Algorithms to Live by (https://www.amazon.com.au/Algorithms-Live-Computer-Science-Decisions/dp/0007547994) , as it’s probably more actionable in my $DayJob
Addendum
After mentioning this book to a friend and trying to summarise pieces, a few pages on Bayesian probability popped up which would have been good, had the book actually made a better point of it. We could probably use this for $DayJob, but it’s not clear how due to this book.